일련의 자료들을 자료 중에 포함된 몇 가지 항목을 우선 순서대로 지정하여 그 순서에 따라 모든 자료를 배열(나열)하는 방법
컴퓨터 공학분야에서 가장 기본적이고 중요한 알고리즘 중의 하나로 자료 탐색에 있어서 필수적
정렬 알고리즘의 종류
버블 정렬 (Bubble Sort)
선택 정렬 (Selection Sort)
삽입 정렬 (Insertion Sort)
쉘 정렬 (Shell Sort)
퀵 정렬 (Quick Sort)
2원 합병 정렬 (Two-way merge Sort)
기수 정렬 (Radix Sort)
힙 정렬 (Heap Sort)
정렬 알고리즘
단순하지만 비효율적인 방법: 삽입 정렬, 선택 정렬, 버블 정렬
복잡하지만 효율적인 정렬: 퀵 정렬, 힙 정렬, 합병 정렬, 기수 정렬
정렬 알고리즘의 평가
비교 횟수
이동 횟수
버블 정렬(Bubble Sort)
레코드가 순서대로 되어있지 않으면 인접한 항목 교환
이웃하는 숫자를 비교하여 작은 수를 앞쪽으로 이동시키는 과정을 반복하여 정렬
방법
a[0]과 a[1]을 비교하여 정렬 순서에 맞도록 교환
a[1]과 a[2]을 비교하여 정렬 순서에 맞도록 교환
…
a[n-2] 와 a[n-1]을 비교하여 정렬 순서에 맞도록 교환
제일 큰 원소가 배열의 n-1 위치로 이동 (1라운드)
배열 처음부터 다시 비교 정렬
버블 정렬 실행 예
버블 정렬 비교 횟수
항목이 4개인 경우
3회 + 2회 + 1회 = 6회
항목의 개수가 N이면 (N-1) + (N-1) + ... +1
N(N-1) / 2
BubbleSort.java
package sort;
public class BubbleSort {
public static void main(String[] args) {
int[] arr = {50, 40, 90, 10};
bubbleSort(arr);
for(int i = 0; i < arr.length; i++){
System.out.println(arr[i] + " ");
}
}
static void bubbleSort(int[] arr){
// 인접한 2개 요소 교환
// 2개의 값을 교환할 경우 변수에 값을 저장하는 순간 이전 값 없어짐
// 이전 값 보존 위해 임시 장소 필요
int temp;
// 총 패스: 배열 크기 -1번 진행
for(int i = 0; i<arr.length; i++){
// 각 패스별 비교 횟수: 배열 크기 - 패스 횟수
for(int j = 0; j<arr.length-i; j++){
if(arr[j] > arr[j+1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
}
선택 정렬(Selection Sort)
잘못된 위치에 들어가 있는 원소를 찾아서 그것을 올바른 위치에 넣는 원소 교환 방식으로 정렬
방법
가장 작은 원소를 찾아 첫 번재 위치의 원소와 교환
두 번째로 작은 원소를 찾아 두 번째 위치의 원소와 교환
첫 번째를 키로 지정하고 뒤 원소와 각각 비교해서 작은 값을 맨 앞으로 보내면 1라운드 종료
두 번째를 키로 지정하고 ~~ (반복)
선택 정렬 실행 예
SelectionSort.java
package sort;
public class SelectionSort {
public static void main(String[] args) {
int[] arr = {9, 6, 8, 7, 5};
selectionSort(arr);
for(int i = 0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
static void selectionSort(int[] arr){
int temp;
// 총 라운드 : 배열크기 -1 번 진행
for(int i = 0; i<arr.length-1; i++) {
// i 다음부터 끝가지 비교
for(int j=i+1; j<arr.length; j++){
if(arr[i] > arr[j]){
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
}
}
삽입 정렬 (Insertion Sort)
배열을 정렬된 부분(앞부분)과 정렬 안 된 부분(뒷 부분)으로 나누고, 정렬 안 된 부분의 가장 왼쪽 원소를 정렬된 부분의 적절한 위치에 삽입하여 정렬되도록 하는 과정을 반복하는 것
방법
정렬되어 있지 않은 부분의 왼쪽에서 삽입할 원소 k를 선택
k를 꺼내서 임시 장소에 넣어 두고 (이동하기 위한 빈자리 확보)
정렬되어 있는 부분에서 k보다 큰 원소들을 오른쪽으로 이동하여 k가 들어갈 빈자리 확보
확보된 빈자리에 k를 삽입
모든 원소들이 정렬될 때까지 반복
정렬 과정
k를 선택해서 이전 위치에 있는 원소들과 비교
첫 번째 위치 원소는 정렬되어 있다고 보고 k는 두 번째 원소부터 시작
k가 이전 위치에 있는 원소보다 작으면 위치 서로 교환
특징
안정된 정렬 방법
많은 이동 횟수: 레코드가 클 경우 불리함
이미 정렬되어 있으면 효율적
삽입 정렬 시간 복잡도
최상의 경우: 이미 정렬되어 있는 경우
비교: n-1번
이동: 2(n-1) 번
최악의 경우: 역순으로 정렬되어 있는 경우(모든 단계에서 앞에 놓은 자료 전부 이동)
비교: n(n-1)/2
이동: n(n-1)/2 + 2(n-1)
삽입 정렬 실행 예
InsertionSort.java
package sort;
public class InsertionSort {
public static void main(String[] args) {
int[] arr = {40, 60, 70, 50, 10, 20, 30};
insertionSort(arr);
for(int i = 0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
static void insertionSort(int[] arr){
for(int i = 1; i<arr.length; i++) {
// 선택한 값 (k에 해당)
int temp = arr[i];
// 현재 선택한 값의 이전 원소의 인덱스 저장
int index = i-1;
// 현재 값이 이전 원소보다 작으면
while(index>= 0 && temp < arr[index]) {
// 이전 원소를 한 칸씩 뒤로 이동
arr[index+1] = arr[index];
index--;
}
// 앞의 원소가 현재 값보다 작으면 반복ㅁ누 종료
// 현재 값은 index 번째 원소 뒤로 와야함
// 따라서 index=1위치에 현재 값 저장
arr[index+1] = temp;
}
}
}
쉘 정렬 (Shell Sort)
원소의 비교 연산과 먼 거리의 이동을 줄이기 위해 몇 개의 서브 리스트로 나누어 삽입 정렬을 반복 수행
삽입 정렬의 개념을 확대하여 일반화시킨 정렬 방법
삽입 정렬의 최대 문제점은 요소들이 이동할 때, 이웃한 위치로만 이동한 것
쉘 정렬에서는 요소들이 멀리 떨어진 위치로도 이동할 수 있기 때문에 쉘 정렬이 삽입 정렬보다 정렬 속도가 빠름
방법
정렬에서 사용할 간격(interval) 결정
전체 원소 수의 n의 1/3, 다시 이것의 1/3, ...
간격이 작아질수록 짧은 거리를 이동하고 원소 이동이 적음
첫 번째 간격에 따라 서브 리스트로 분할
각 서브 리스트에 대해 삽입 정렬 수행
두 번째 간격에 따라 서브 리스트로 분할
각 서브 리스트에 대해 삽입 정렬 수행
리스트 전체에 대해 삽입 정렬 수행(마지막 간격은 1)
쉘 정렬 실행 예
ShellSort.java
package sort;
public class ShellSort {
public static void main(String[] args) {
int[] arr = {30, 60, 90, 10, 40, 80, 40, 20, 10, 60, 50, 30, 40, 90, 80};
shellSort(arr);
for(int i = 0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
static void shellSort(int[] arr){
int N = arr.length;
for(int h=N/2; h > 0; h/=2){
// 삽입 정렬을 하기 위해 서브 리스트의 두 번째 값을 가지고 비교
for(int i=h; i<N; i++){
int idx = i-h;
int temp = arr[i];
// 삽입 정렬 수행
while(idx >= 0 && arr[idx] > temp) {
arr[idx+h] = arr[idx];
idx -= h;
}
arr[idx + h] = temp;
}
// 각 간격마다 정렬 결과 확인
for(int a : arr) {
System.out.print(a + " ");
}
System.out.println();
}
}
}
퀵 정렬
분할 정복 정렬 방법의 하나
전체 리스트를 2개의 부분 리스트로 분할하고
각각의 서브 리스트를 다시 퀵 정렬로 정렬
기준 값보다 큰 값들은 오른쪽으로, 작은 값들은 왼쪽으로 재배열
방법
전체 리스트에서 한 원소를 기준 값(pivot)으로 선정
피벗을 기준으로 두 개의 서브 리스트로 분할
왼쪽 서브 리스트: 피벗보다 작은 값의 원소들로 구성
오른쪽 서브 리스트: 피벗보다 크거나 같은 값의 원소들로 구성
각각의 파티션(서브 리스트)에 대해 다시 퀵 정렬을 순환 적용
피벗 선정 및 파티션 분할
퀵 정렬 수행 순서
피벗(pivot): 가장 왼쪽 숫자를 피벗으로 선정
두 개의 변수: low와 high(이동)
low는 왼쪽에 위치
high는 오른쪽에 위치
low: 오른쪽으로 이동하면서 피벗보다 큰 숫자를 찾음
피벗보다 작으면 통과, 큰 숫자를 찾으면 정지
high: 왼쪽으로 이동하면서 pivot보다 작은 숫자를 찾음
피벗보다 크면 통과, 작은 숫자를 찾으면 정지
정지된 위치의 숫자들을 서로 교환
low와 high가 교차하면 종료, high와 pivot 교환
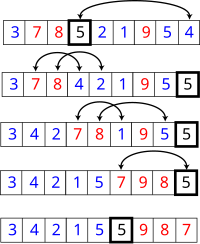
퀵 정렬 실행 예
QuickSort.java
package sort;
public class QuickSort {
public static void main(String[] args) {
int[] arr = {3, 7, 8, 5, 2, 1, 9, 5, 4};
quickSort(arr, 0, arr.length-1);
for(int i = 0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
static void quickSort(int[] arr, int low, int high){
if(low >= high) return;
int pivot = low;
int i = low + 1;
int j = high;
int temp;
// 교차할 때까지 반복. j가 i보다 크면 while문 종료
while(i <= j){
// 피벗보다 큰 값을 만날 때가지 반복
while(i<=high && arr[i] < arr[pivot]){
i++;
}
// 피벗보다 작은 값을 만날 때까지 반복
while(i>low && arr[j] >= arr[pivot]) {
j--;
}
// 교차한 상태가 되면 -> 피벗과 j값 교환
if(i > j){
temp = arr[j];
arr[j] = arr[pivot];
arr[pivot] = temp;
}
// i와 j 교환
else {
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
quickSort(arr, low, j-1);
quickSort(arr, j+1, high);
}
}
2원 합병 정렬(Two-way merge)
정렬된 2개의 리스트를 혼합하여 완전히 정렬된 하나의 리스트로 합하는 정렬 방식
2원 합병 정렬 실행 예
기수 정렬(Radix Sort)
정렬할 원소의 키 값을 나타내는 숫자의 자릿수(radix)를 기초로 정렬하는 기법(사전식 정렬 방법)
정렬하려고 하는 값을 버킷에 넣어 정렬
버킷으로 큐 사용
이터가 입력되는 곳, 출력되는 곳: 먼저 들어온 것이 먼저 출력
프린터, 은행 번호표
버킷의 개수는 키의 표현 방법과 밀접한 관계
이진법을 사용한다면 버킷은 2개
알파벳 문자를 사용한다면 버킷은 26개
십진법을 사용한다면 버킷은 10개
방법
첫 번째 패스 (1라운드)
정렬할 키의 가장 작은 자릿수를 기준으로 분배 정렬
두 번째 패스
두 번째 작은 자리수를 기준으로 분배 정렬
키 값이 같은 경우 이전 정렬에서의 순서를 그대로 유지
키의 가장 큰 자릿수까지 반복 수행
1자리 수의 기수 정렬 실행 예
단순히 자리 수에 따라 버킷에 넣었다가 꺼내면 정렬됨
두 자리 수의 기수 정렬 실행 예
일의 자리 수
십의 자리 수
초기 리스트: a = [35, 81, 12, 67, 93, 46, 23, 26, 21]
힙 정렬 (Heap Sort)
정렬할 원소를 힙(heap)이라는 자료 구조를 이용하여 정렬하는 방법
힙 구조
완전 이진트리로서 각 노드의 키 값이 자식 노드들의 키 값보다 작지 않은 트리
힙 루트는 트리 중 가장 큰 값을 나타냄
방법
주어진 데이터로 이진트리 구성
힙 구조 알고리즘과 힙 정렬 알고리즘을 수행
힙 구조 알고리즘
제일 늦게 구성된 트리 선택
부모 노드와 자식 노드 중 가장 큰 값 선택
부모 노드와 자식 노드 중 가장 큰 값을 비교하여 자식 노드가 크면 서로 위치 교환(큰 값을 위로 보냄)